
はじめに
皆さんは、ChatGPTやBingなどの生成型AIをどう利用していますか?
PCやスマートフォンの文字入力で使っている方が多いのではないでしょうか。今、AIとのコミュニケーションとして文字入力ではなく音声入力の方法も増えており、より生に近い即応性の高い対話が可能となっ増えており
AIを活用する上で、音声入力(音声認識)という選択肢を持っていることは非常に重要です。
何故なら、
AIと音声入力は相性がバツグンだからです。
音声認識モデルとは?
音声認識モデルとは、AIが人間の声を認識し、認識した音声をもとにアウトプットする技術のことです。音声認識モデルは、スマートフォンやスマートスピーカーなどの音声操作インターフェースや、ビデオ会議や録音の文字起こしや翻訳などの応用分野で活用されています。
音声認識モデルの性能は、単語誤り率 (WER) や文字誤り率 (CER) などの指標で評価されます。単語誤り率は、音声認識結果と正解文との間で、間違った単語の数を正解文の単語数で割ったものです。文字誤り率は、同様に文字単位で計算したものです。
参考まで、人間が文章を読んで意味が分かるレベルは単語誤り率で75%以上が必要であり、音声認識モデルとして実利用する上では、議事録では85%以上、アナウンサーの原稿読み上げは95%以上の性能が必要であるとされています。
音声認識モデルの歴史は古く、1970年代から研究が始まりましたが、当初は精度が低くて一般に普及しませんでした。しかし、2000年代になってアルゴリズムの改善により精度が向上し、カーナビやパソコンなどに搭載されるようになりました。さらに、2010年代に入ってAIの「深層学習(ディープラーニング)」という手法が音声認識モデルにも取り入れられるようになり、精度は飛躍的に向上しました。深層学習とは、大量のデータからAI自らが自律的にパターンを学習手法であり、従来人間が教えていたパターン分けをAI自らが特徴を抽出して学習することが可能となりました。
発展する音声認識モデル
現在では、GoogleやOpenAIなどの企業や研究機関が最先端の音声認識モデルを開発しています。
例えば、Googleは2022年5月に「コンフォーマー」という新しい音声認識モデルを発表しました。このモデルは、音声の認識、単語や文章のパターン認識、イントネーションや方言などの認識という3つの要素をそれぞれ個別に学習させるのではなく、1つのニューラルネットワークで一気に学習させることを実現しています。
また、OpenAIは2022年9月に「Whisper」という汎用的な音声認識モデルを発表しました。このモデルは、68万時間もの大規模データセットを用いて学習されており、多言語音声認識や機械翻訳・音声区間検出等のマルチタスクにも対応しています。
音声入力”Whisper”を使ってみた
OpenAIが作ったWhisperは、すでにChatGPTのアプリと連携しています。ChatGPTのスマートフォンアプリでプロンプトを入力する時に、入力欄右側の縦6本線をタップする(画像左)と、音声入力が開きます(画像右)。
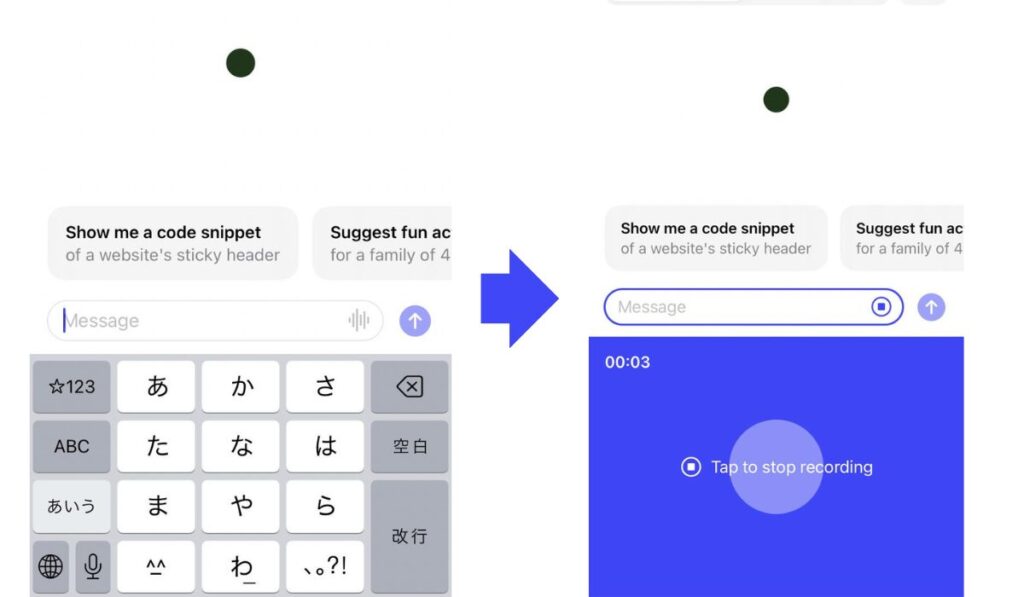
試しに、本記事の冒頭文を読み上げてみました。その結果が以下です。
どうでしょう?ほとんど完璧に近く文字起こしができていますね。
はじめに、皆さんはChatGPTやBingなどの生成型AIを どう利用していますか? PCやスマートフォンの文字入力で使っている方が 多いのではないでしょうか? 今、AIとのコミュニケーションとして、文字入力ではなく 音声入力の方法も増えており、 より生に近い速応性の高い対話が可能となっています。 AIを活用する上で、音声入力、音声認識 という選択肢を持っていることは非常に重要です。 なぜなら、AIと音声入力は相性が抜群だからです。
まとめ
今回は、音声入力を可能にするモデルとChatGPTでの使用方法を紹介しました。人間とAIの対話がより自然で快適なものになれば、その活用方法は無限です。
ブログ記事の速記、アイデアのメモ、十分に言語化されていない考えの整理など、よりクリエイティブな使用が可能になります。
次回は、実際に音声入力を活用したAIの利用方法について紹介したいと思います。
AIと共に未来を創る!


コメント